Introduction
Mining unstructured data and converting it to structured data with context is a major challenge for organizations that need to summarize or process information from documents. Hierarchical Clustering is an approach that uses statistical functions that provide information about the proximity of words and symbols close together.
This article was written for developers who want to explore how clustering can be used on data to find specific information without knowing the full structure of the document.
Problem Statement
The challenge is to find a specific data subset and categorize it without form elements or labels. Documents could have multiple pages where each page could have different font types, sizes, and orientation. This project explores the challenge of finding a valid US street address inside of a document without any prior knowledge about the document layout or format.
Solution
Clustering quickly group words physically positioned on the page in close proximity. Inspecting the clusters for “markers” (words contextually related to US addresses) is the approach taken.
The solution uses a clustering routine to separate the document content into clusters of words related by their Euclidean Distance from each other.
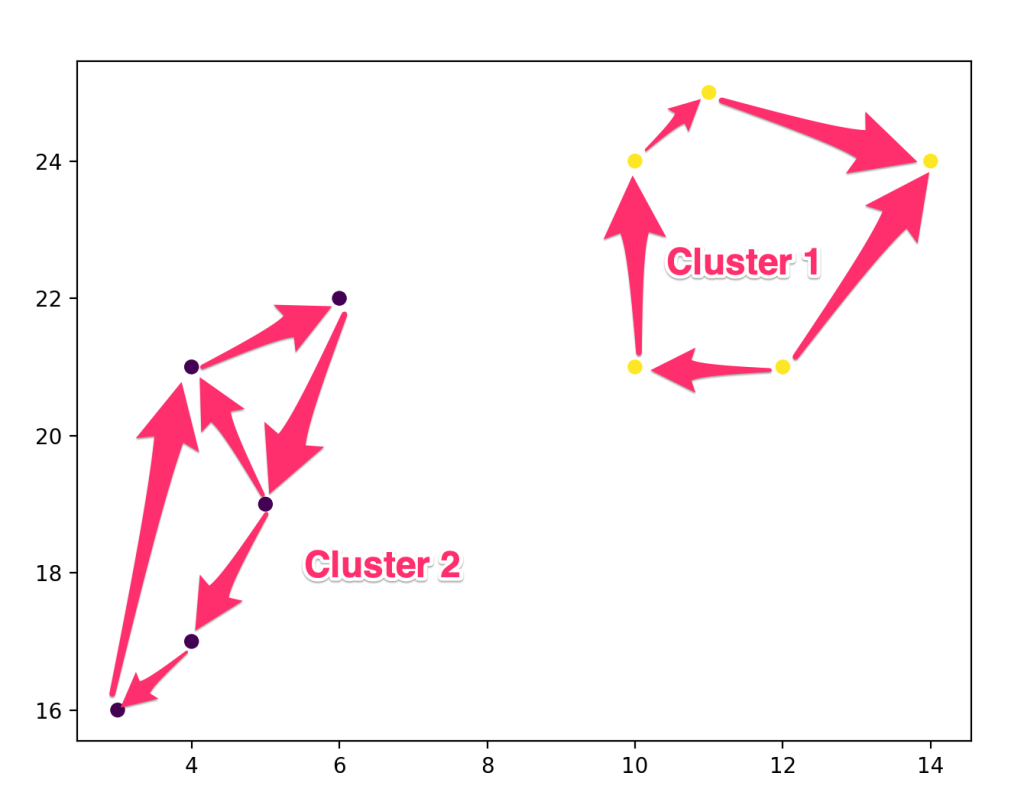
the figure above was generated using a basic routine that uses the Scipy library and its hierarchical clustering function. The examples are in this project. If the yellow and black points represented words in a document, then it could be possible that the words within each cluster are contextually related, in this case, a valid US address.
This clustering routine starts by creating clusters for every point then calculate the distance between other points and combine them into larger clusters until you have a cluster uniquely distinct by distance. Notice that the points in Cluster 1 have comparable distances from each other and the same is observable in Cluster 2. Read more about the linear algebra that further details specifics about calculating the distance between points from here.
Once the final clusters form, the next task is to parse the clusters for a marker contextually related to addresses. I created a simple, short, vocabulary contextually related to addresses using words like ‘street’, ‘avenue’, ‘lane’, ‘road’… This limited vocabulary allows the routine to quickly rule out any clusters that don’t have a combination of a vocabulary word, zip code, or US state. At this point there is still no clear way to differentiate between street numbers, street names, and cities (there could be the thousands) so a generic, catch all category was created called ‘other’ denoted by ‘o’.
An analysis of the initial data from the document reveals a view factors to consider regarding US addresses. Valid addresses always have two parts that are fairly easy to find which include zip codes and states (regions). A simple array could be used as the data structure to hold the 50 states of the US. The zip code has several concrete attributes that include:
- numeric
- standard format
- only two variations for zip code 5 and 9 digits (with a hyphen)
The possible outcomes for U.S. anddresses are represented by a three bit truth table and a K-Map analysis to derive an expression to output possible addresses. See the truth table below
v – vocabulary word
s – us state
z – zip code
o – other
! – Vocabulary words were chosen as the most significant digit in the truth table because it is directly related to a valid address so the rule is to always investigate lines with a vocabulary word
| v | s | z | K-Map Results |
| 0 | 0 | 0 | |
| 0 | 0 | 1 | |
| 0 | 1 | 0 | |
| 0 | 1 | 1 | sz |
| 1 | 0 | 0 | ! v |
| 1 | 0 | 1 | vz |
| 1 | 1 | 0 | vs |
| 1 | 1 | 1 | vsz |
Business Logic Rule
Vocabulary words will always trigger address processing. The presence of a zip code and state, any combination from these three variables that has at least two words in these categories, or when we have all these categories of words together. The results of a K-Map are indicated beside particular rows in the truth table where there is a desired output and used to create boolean the expression below:
Some of products (SOP)
v+sz+vz+vs+vszThese are the combinations that will output words that together make up a US street address.
Data structures
The details on how to implement the SOP are left for another discussion however during the process of the text data in the document, you will need to use arrays, objects, counters, and loops to partition the data up into this
format:
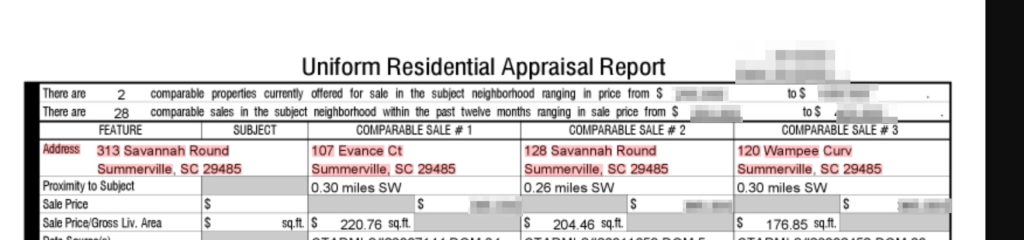
[‘313’, 90, 136, 109, 145, 16, 2, 1, ‘num’, ‘o’],
[‘Savannah’, 113, 136, 165, 145, 16, 3, 1, ‘str’, ‘o’],
[‘Round’, 170, 136, 202, 145, 16, 4, 1, ‘str’, ‘v’],
[‘Summerville,’, 274, 152, 340, 162, 16, 17, 2, ‘str’, ‘o’],
[‘SC’, 345, 152, 360, 160, 16, 18, 2, ‘str’, ‘s’],
[‘29485’, 365, 152, 396, 160, 16, 19, 2, ‘num’, ‘z’],
Above is a partial output from a document where a small routine has formatted the data from the document into Python Lists with the following data format for each word:
| element position | value category |
| 0 | text |
| 1 | x-coordinate |
| 2 | y-coordinate |
| 3 | width |
| 4 | height |
| 5 | font size |
| 6 | x word position |
| 7 | y word position |
| 8 | datatype |
| 9 | category (v,s,z,o) |
Notice that this will work for addresses on multiple lines too. The address is in the document on two lines of text (y word position in example address). The data has all the information to accurately locate the word on the document along with the size of the characters and category.
Conclusion
Clustering helps get to the desired data fast by combining characters and words to form clusters of words close in location together. Using a small vocabulary with unsupervised learning model can put unstructured data into context. Other data can be categorized using the same approach using the data attributes to derive a logical expression.
To Do
Search and categorize prices
Combine the unsupervised model with a supervised model that could extend the vocabulary after processing an amount of data and categorizing it.
Use other data attributes such as word position to further refine search routines and data formats.
Leave a Reply